Utano's nonsense or IT news or Game replay or Diary or etc. write as my feel, It is that a site.
皆様いかがお過ごしでしょうか。歌乃です。
ComfyUI で SDNQ 関連機能を使用できるようにしてみました。
といっても単に以下のカスタムノードを追加しただけでございます。
https://github.com/EnragedAntelope/comfyui-sdnq
※いつもどおり大半が戯言です( ゚Д゚)
皆さまいかがお過ごしでしょうか。歌乃です。
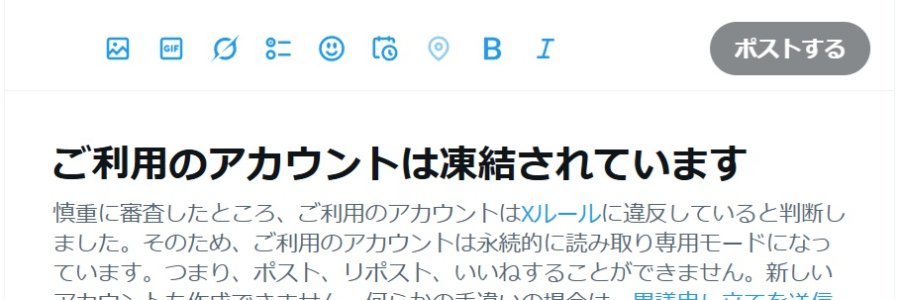
1年ぶり二回目のアカウント凍結です(*ノωノ)
※いつにもまして戯言で出来ています。

皆様いかがお過ごしでしょうか。歌乃です。
活動場所がすっかり X に移行してしまって、向こうでひたすらPOSTする毎日です( ゚Д゚)
まあ、SNS も良し悪しで、実行環境的に、自分にしかわからないことをつぶやいても全く反応を得られません。
まあ当たり前ですね。
広く浅く、最大公約数的な情報、つまりは誰もが共感したり反発できたり、わかりやすいものが受ける、という気がします。
批判ではなく純粋な分析で、こうすればこうなるんじゃないか、というのを日々、利用規約の制限の中で試行錯誤しております。
※(いつにも増して戯言です、そしてこの記事は書きかけ、現在進行中なので、後で内容が変わる可能性が高いです)

皆さまいかがお過ごしでしょうか。歌乃です。
書いたつもりですっかり忘れていました( ゚Д゚)
タイトル通りの内容と、解決策というか対処法に関してです。
※今回は戯言少なめな内容でお送りしております。
皆様いかがお過ごしでしょうか。歌乃です。
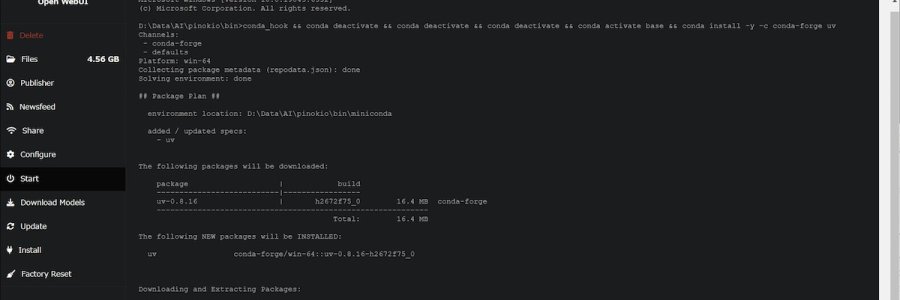
Server application (主に LLM、MLM 関連) マネージャーとして pinokio を利用しています。
以前 Stability Matrix を利用していたのですが、あちらは画像生成ワークフレームが主で、その他のワークフレーム (動画や音声、テキスト生成など) は見かけません。
ComfyUI を使えば、動くものもありますが (むしろ大抵のものは動く)、やはり、専用のワークフレームの方がなにかと都合がいいのも事実です。
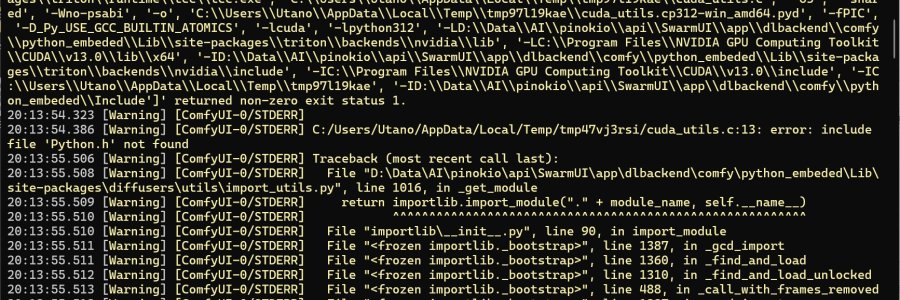
ということで pinokio に乗り換えて使い倒していたのですが、python 関連の断捨離を決行したところ、問題が発生 (発覚) しました。
※いつものごとく九割方、戯言で構成されています。
皆様いかがお過ごしでしょうか、歌乃です。
久々の記事投稿です。
忙しいというか、それだけ充実した日常だったのだと思います (思いたい) 。
さて、相変わらず、LLM関連のあれやこれやを勉強中です。
そしてそれらの基礎技術として python が必要になります。
もう、息をするように python が使えないと話になりません ( ゚Д゚)
しかし、元来記憶力が微妙な私はいろいろと覚えきれないので備忘録としてここに記しておきます。
※いつものごとくほぼ、戯言です。
皆様いかがお過ごしでしょうか。歌乃です。
作業用アシスタントとして Ollama にて Open Web UI を通して使用 (試用) した 日本語対応可能 LLM の所感です。
※個人的な主観と偏見が大いに含まれています。ご注意ください。
皆様いかがお過ごしでしょうか。歌乃です。
7月ですが、すでに真夏のように暑いですね。
そして、トカラ列島の地震が心配ですね (´・ω・`)
この記事は個人的な備忘録です。
元となった source は削除されていなければ https://stackoverflow.com/questions/20711240/how-to-completely-remove-node-js-from-windows にあります。
皆様いかがお過ごしでしょうか。歌乃です。
私のPCはいわゆる自作PCでございます。
パーツを一つづつ自分で選んで、組み上げて、PCとして稼働するようにしたわけです。
自作PCのいいところは強化したい部分に良いパーツを、そうでもないところは安いパーツまたはパーツ自体を省く、といった自由度の高い構成ができるところです。まあ、ショップのBIO (ビルトインオーダー) でも似たようなことはできるんですが (´・ω・`)
ある程度自作 PC の知識がある方向けの内容になっています。
(今回も大半は戯言です)
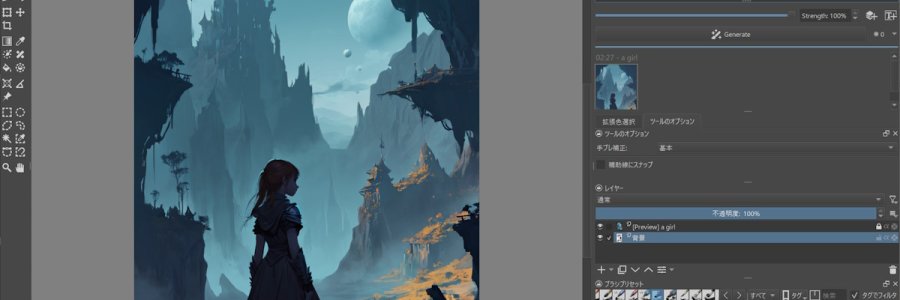
皆さまいかがお過ごしでしょうか。歌乃です。
ちょっとした画像の修正や加工に、Paint 3D というアプリを使っていました。Microsoft 公式で windows 10 に標準搭載されたアプリだったのですが、残念なことに2024年の11月に廃止になってしまい、とうとう起動も再インストールもできなくなってしまいました。(´;ω;`)
気軽に使えるお絵かきアプリとしては windows 標準の paint がありますが、微妙に使いにくいんですよね(´・ω・`)
ということでそこそこ高機能で手軽に使える paint アプリはないものかと探していたところ、Krita に出会いま...